
Nikhilesh Ghushe is involved in research, which is focused on inventing new abstractions and formalisms, to be used in computer science, inspired from the understanding of human comprehension of natural languages, as described in Navya-Nyaya and Vyaakaran.
How has family’s interest and erudition in Sanskrit sparked your interest in the language.
I come from a family of Sanskrit scholars. My father was a Vaiyyakarana (वैय्याकरण) who studied in Kashi in the Guru-Shishya tradition. He was taught Vyaakaran (व्याकरण) and Navya-Nyaya (नव्यन्याय) from a very early age, as was the norm in those days for anyone starting to learn Shastras (शास्त्र). He was also exposed to related Shastras such as Mimansa (मीमांसा) and Vedanta (वेदांत), especially Shabdadvaita (शब्दाद्वैत).
He never went to a modern school, and because of that remained uncorrupted by the modern world-view, which implicitly infects the minds of most of us who studied in the current education system. For my father, even basic concepts like the concept of a number, a place, a thing, or time, came from the tradition, not from the modern scientific world-view. This led me to see most things from two different perspectives. One that the school taught me, and the other the way my father saw. I developed an early sense that the school is not giving me the full picture, and there are other ways of looking at things.
Another important factor was that my father, and his friends from Kashi, exposed me to Hindi poetry at an early age. I loved Hindi poets like Jaishankar Prasad, Mahadevi, Nirala, Maithilisharan, Hariaudha, Pant, Dinkar etc who wrote in Sanskritized Khadi Boli. I learnt a lot of Sanskrit vocabulary, almost like a leisure fun activity, with no stress.
You mention a deep interest in Shaiva Darshan, and specifically the Pashupat and Pratyabhigya tradition. Bhartrhari makes a connect saying language is the sheath that covers metaphysics. What are your thoughts on this?
I am extremely pleased to get this question. :) My father was fascinated with Bhartrihari’s Vaakyapadiyam (वाक्यपदीयम्). He has given lectures during his tenure as a professor, suggesting that Bhartrihari’s Shabdadvaita (शब्दाद्वैत) can be considered a Nirishwarawadi (निरीश्वरवादी) expression of Kashmira Shaiva Darshan (काश्मीर शैव दर्शन). And hence, they should be treated like the pairs of Mimansa-Vedanta (मीमांसा-वेदांत), Saankhya-Yoga (सांख्य-योग), and Vaisheshika-Nyaya (वैशेषिक-न्याय). Though I have not fully studied Vaakyapadiyam, I have read its Brahmakanda (ब्रह्मकाण्ड), and have skimmed through the other two Kandas. Also, my personal spiritual interest led me to the Shiva Sutras (शिवसूत्र)of Vasugupta. And to both my joy and surprise, the first three Karikas of Vaakyapaidyam, have a correspondence with the first three Shiva Sutras. I think the best way to answer this question would be to write my interpretative translations of the six of them, followed by a note to bring it together.
First three Shiva Sutras
चैतन्यमात्मा ॥१॥
Awareness (that which knows) is the self.
ज्ञानं बन्धः ॥२॥
Knowledge (that which is being known) enslaves.
योनिवर्गः कलाशरीरम् ॥३॥
Category of the birth-womb, and tendencies, is the body.
First three Karikas of Vaakyapadiyam
अनादिनिधनं ब्रह्म शब्दतत्त्वं यदक्षरम्। विवर्ततेऽर्थभावेन प्रक्रिया जगतो यतः॥१॥
The imperishable essence of the beginning and end-less Brahma is Shabda (The Word), and it manifests as the process of the world, through the arising of meaning.
एकमेव यदाम्नातं भिन्नं शक्तिव्यपाश्रयात्। अपृथक्त्वेपि शक्तिभ्यः पृथक्त्वेनेव वर्तते॥२॥
That (Shabda) which the Vedas describe as one, becomes manifold by Shakti (the meaning-arising power) residing in it, and thus, even though being undifferentiated, because of Shakti, becomes differentiated.
अध्याहितकलां यस्य कालशक्तिमुपाश्रिताः। जन्मादयो विकाराः षड् भावभेदस्य योनयः॥३॥
The power of time, which is an inherent tendency of Shabda, sustains within it the six types of actions (meanings of verbs) - beginning, being, changing, growing, decaying, and ending - which, in turn, are the wombs of the manifold objects (meanings of nouns).
Semblance between Kashmir Shaiva Darshan and Shabdadvaita
So for the Shabdabrahmavadis (शब्दब्रह्मवादी) like Bhartrihari, awareness or Atma (आत्मा) is shaba-tatva. In other words, substratum of our awareness is Shabda. Shabda means both sound and word, but not in the sense of merely the physical vibrations of air, but the essence of that vibration. Let’s say we hear the sound “Ram” at two different occasions. Once from someone talking to us, and second time as a part of a song we hear on our mobile. We identify the two sounds as the same, even if they might have different loudness, or they may be coming through different mediums, and are created by different sources. Why? because by sound, we don’t mean a particular physical occurrence of vibration, but its essence which we identify as the common across its multiple physical occurrences.
This “essential” Shabda carries the power to evoke a meaning. This is analogous to how awareness (or Aatma) has the capacity to arise knowledge within it. If we perceive intensely, we can see that there is always an underlying presence of sound in our awareness. For instance, there is always a background noise going on, that we don’t necessarily notice. There might be a song playing somewhere far away, a buzz of a machine, or traffic noise. Even in our dreams and in our sleep, there is an unnoticed background noise. This is a single continuous presence. Only when we hear a meaning-carrying sound, let’s a say a sentence uttered by someone in front of us, then we divide that single continuous presence into chunks of sounds, based on what meaning those chunks evoke. We call these chunks individual words.
This is exactly analogous to the continuum of reality that is one single whole, which we divide in to individual phenomena by giving it names. Where does a tree start and where does the soil end? Where does the ocean end, and the air above it begin? It depends on how have we named the phenomena. If we are using the word forest, both the tree and the soil are included in it. Only when we bring our attention to specific words - “tree” or “soil”, then our mind divides the continuous reality, abstracting out chunks meant by those words. Observing how a child learns words, can be very instructive in this regard. This is analogous to one single awareness, appearing as many, based on the different things it knows. One Jeevatma is separate from the other, only because they know different things. And thus the knowledge-arising power of Aatma, is analogous to meaning-evoking power of the Shabda, and both result in dividing of a single continuum.
In addition to this ability to evoke meaning, the Shabda also has the power to give order (क्रम) to the divided chunks. This is the power of time. Because of this power of time, we are able to abstract out the phenomena we call “actions”, from the single continuum of reality. Actions are meanings of verbs. These actions further give rise to the naming of distinct objects, as different from one another. The object of eating is food, the object of going is place, so on and so forth. Objects are meanings of nouns. Thus, according to Bhartrihari, the continuum of reality is first divided into meanings of verbs, and these verbs, then give rise to the perceptions of meanings of nouns. That is why most nouns have their etymology in verbal-roots. This is analogous to Jeevatmas differentiated from a single awareness based on knowledge, further acquiring a body, based on it’s tendencies (which are actions and hence meanings of verbs). The physical bodies, which are objects and hence meanings of nouns, are a result of the tendencies of the Jeevatma.
Thus, Shabda-Artha and Shiva-Shakti are just different ways of looking at the same underlying reality.
You are the Co-founder of AcquiredLang (https://www.acquiredlang.com), a stealth mode research startup working on the overlap between Artificial Intelligence, Nyaya Darashan, and Sanskrit Vyakaran. Do you think bringing IKS to AI will help make AI more representative and ‘ethical’. What role does epistemology in Nyaya Darashan play in developing AI systems capable of better decision-making and knowledge representation?
Our research so far, has been more on the side of inventing new abstractions and formalisms, to be used in computer science, inspired from the understanding of human comprehension of natural languages, as described in Navya-Nyaya and Vyaakaran. Our focus has been on bringing theoretical clarity, consistency, and exhaustiveness to the understanding of human comprehension of natural languages, so that it becomes accessible to the computer scientists. The following are a few representative concepts from which we have taken inspiration for this purpose:
- Navya-Nyaya-Paribhasha (नव्यन्यायपरिभाषा) - a canonical subset of the Sanskrit language, used for unambiguously describing all types of human cognition, including comprehension.
- Shabdabodh (शाब्दबोध) - method of describing comprehension of Sanskrit utterances, using the Navya-Nyaya-Paribhasha.
- Prakaar-Sansarga-Visheshya (प्रकार-संसर्ग-विशेष्य) - a fundamental unit of Navya-Nyaya-Paribhasha, and hence by extension a unit of knowledge representation.
- Karya-Kaarana-Bhaava (कार्य-कारण-भाव) and Kaarana-Mimansa (कारणमीमांसा) in Nyaya - the Theory of Causation in Navya-Nyaya, developed from the much older Vaisheshika tradition.
Based on the work so far, we are confident that thorough research in IKS, we can bring far greater expressivity to knowledge representation, and explainability to AI decision-making. However, it is hard to say whether it will make AI more ethical.
How can principles of Nyaya Darashan be used to enhance the logical reasoning capabilities of AI systems? In what ways can combining the logical structure of Nyaya and the linguistic rules of Sanskrit Vyakaran lead to advancements in AI-driven language models? What are the benefits of using ancient Indian logic (Nyaya) compared to Western logic systems in AI frameworks?
I am combining the above three questions and answering them together in one long answer.
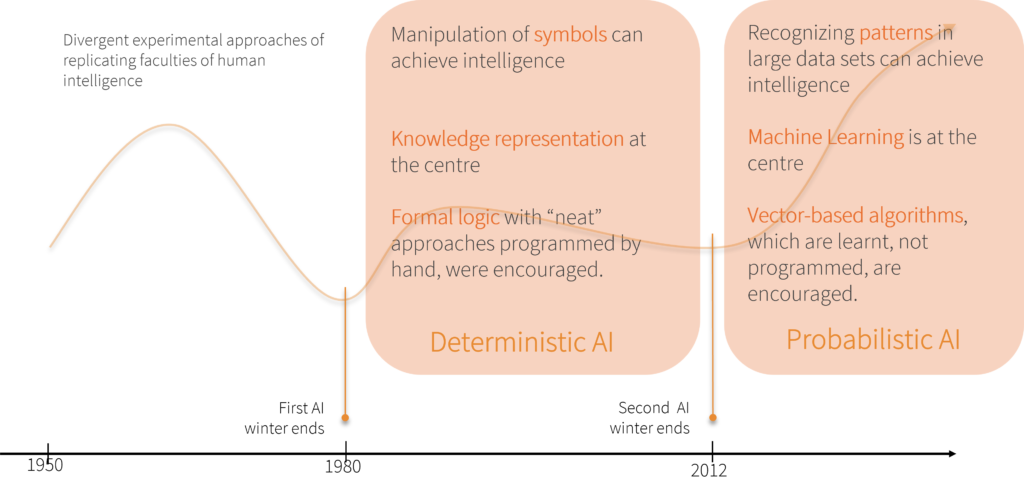
If we have a historical look at development of AI since the 1950s, we can roughly divide it in three phases (shown in the image above):
- From the 50s to the late 70s - when a diverse set of approaches were tried, with success primarily thwarted by non-availability of good-enough hardware.
- From early 80s to 2012 - when Deterministic AI was in focus, with the following salient points:
- A fundamental belief that “manipulation of symbols can achieve intelligence”.
- Knowledge Representation was at the centre.
- Algorithms based on formal logic, programmed by hand, were encouraged.
- From 2012 till present - when Probabilistic AI is in focus, with the following salient points:
- A belief that “recognising patterns in large data sets can achieve intelligence”.
- Machine Learning is at the centre.
- Vector-based algorithms, which are learnt, not programmed, are encouraged.
The deterministic approach did not prove to be successful in representing and fruitfully analysing complex human experiences. Looking back, it seems that the available forms of formal logic were not a natural fit for representing the entire gamut of human experiences. I will come back to it later below.
The age of Probabilistic AI was started with Prof. Geoffrey Hinton’s seminal work that invented deep-learning. This phase can be further divided into two sub-phases:
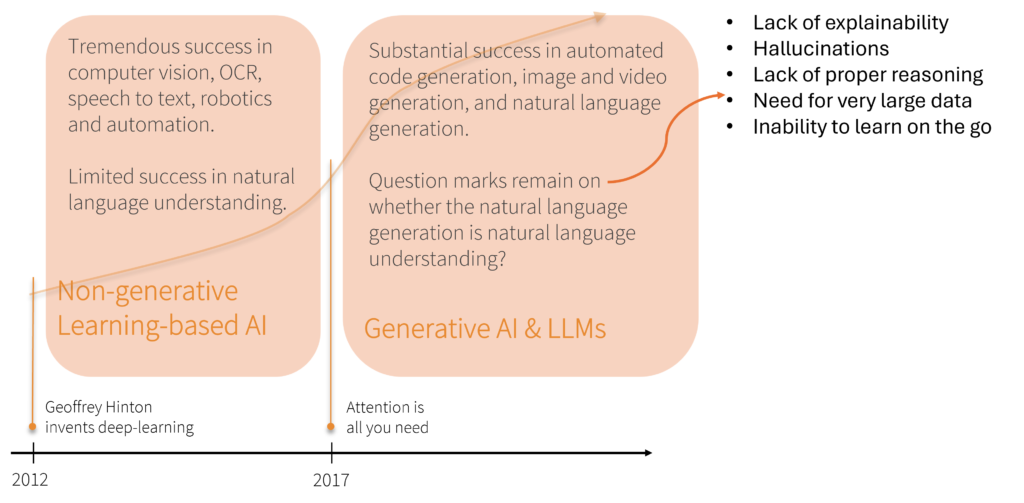
- From 2012-2017: Deep-learning based algorithms achieved tremendous success in computer vision, OCR, speech-to-text, robotics and automation, but had limited success in natural language understanding. Vector-based probabilistic systems deal with many aspects of reality far better than symbolic logic. Probably because vector algebra developed as means of describing the physical properties of the real-world, and hence were effective in dealing with colours and sounds, but less so with words and meanings.
- From 2017 onwards: Starts with the seminal work on Attention-based techniques which led to creation of LLMs, which achieved substantial success in automated code-generation, image/video generation, and natural language generation. The LLMs are great retrieval machines, and when fed with a very large amount of information, they can pick an appropriate response from this already vectorized and digested information. But they are not very great at combining information to retrieve new results, because of they need millions of instances of something to learn a generalized pattern, which a small child can grasp with 3-4 examples. And therefore, question marks remain on whether natural language generation is natural language understanding? Inability to explain its outcomes, hallucinations, lack of proper reasoning, need for very large data, and inability to learn on the go are some of its principal drawbacks. We can see leading people in AI saying this already:
 In my opinion, most of these drawbacks actually stem from a single issue, that there is no symbolic semantic model backing these Probabilistic AI systems. By symbolic semantic model, I mean a well-defined set of symbols and rules shared between both humans and machines. In the absence of such a symbolic model, humans will never feel fully confident, that the machine understands them. So this brings us back to the question - why did the symbolic systems, from the Deterministic era did not achieve much success dealing with the diverse set of human experiences. My conjecture is, because the systems of logic used for them were inadequate.
In my opinion, most of these drawbacks actually stem from a single issue, that there is no symbolic semantic model backing these Probabilistic AI systems. By symbolic semantic model, I mean a well-defined set of symbols and rules shared between both humans and machines. In the absence of such a symbolic model, humans will never feel fully confident, that the machine understands them. So this brings us back to the question - why did the symbolic systems, from the Deterministic era did not achieve much success dealing with the diverse set of human experiences. My conjecture is, because the systems of logic used for them were inadequate.
Currently, what we call symbolic logic in computer science (also called formal logic), is based on fundamental works by stalwarts such as George Boole, Gottlob Frege, Kurt Gödel, and John von Neumann. These systems of symbolic logic deal with idealized mathematical objects, such as “propositions” and “predicates”. A proposition is supposed to be a unit of knowledge, to which a truth value can be assigned. A predicate is suppose to be a template of knowledge, with unfilled variables. When we substitute variables with values in a predicate, we get a proposition - a statement which can be ascertained to be true or false. But it does not serve well as a template of a generic natural language sentence, because it falls short of accommodating the full complexity and content of what a human can understand from a sentence. What we humans call context is not formalized in these predicate based systems of logic. More complex systems, such as Modal and Temporal logics, attempted to accommodate some of these ideas, but they all either fall short, or end up being too complex and inelegant for humans.
This is not to take away from the great achievements of symbolic logic, which has resulted in the development of the field of computer science, and served as the basis of so many software infrastructures such as many programming languages, and databases. This is just to convey that, for meeting the current expectation of AI, we need to look for new kinds of symbolic logic which are not restricted to dealing with idealised mathematical objects.
Another aspect of this “idealisation” is that the logic itself only deals with the “form” of logical discourse, not the content of it. In words of Bimal Krishna Matilal:
Thus, the basic features of Western logic are: It deals with a study of ‘propositions’, specially their ‘logical form’ as abstracted from their ‘content’ or ‘matter’. It deals with ‘general conditions of valid inference’, wherein the truth or otherwise of the premises have no bearing on the ‘logical soundness or validity’ of an inference. It achieves this by taking recourse to a symbolic language that has little to do with natural languages.
The main concern of Western logic, in its entire course of development, has been one of systematizing patterns of mathematical reasoning, with the mathematical objects being thought of as existing either in an independent ideal world or in a formal domain.
Indian logic, however, does not deal with ideal entities, such as propositions, logical truth as distinguished from material truth, or with purely symbolic languages that apparently have nothing to do with natural languages. The central concern of Indian logic as founded in nyāya-darśana is epistemology, or the theory of knowledge. Thus Indian logic is not concerned merely with making arguments in formal mathematics rigorous and precise, but attends to the much larger issue of providing rigor to the arguments encountered in natural sciences (including mathematics, which in Indian tradition has the attributes of a natural science and not that of a collection of context-free formal statements), and in philosophical discourse.
In this context, Navya-Nyaya can be of great value. Navya-Nyaya serves that place in Indian knowledge tradition, which is played in the West by Epistemology, Ontology, Cognitive Science, and Logic. Indian tradition does not treat these areas in silos, but brings all of them in a single coherent whole, largely thanks to the work of Gangeshopadhyaya (गङ्गेशोपाध्याय) of Mithila. Gangeshopadhyaya combined the earlier Sutra-based tradition of Nyaya with the tradition of Vaisheshika (वैशेषिक), and wrote the Magnum Opus Tattvachintamani (तत्वचिन्तामणि). Tattvachintamani is a single coherent exposition of how humans acquire knowledge, which includes: how we perceive through our senses, how we apply logic on the perceived knowledge to infer new knowledge, what is the form of the knowledge acquired through these different means, and what is the ontology covering all possible objects that make up this knowledge.
Navya-Nyaya has two unique advantages to serve as the basis of symbolic systems of logic underlying AI systems:
- It does not separate the “form” from the “content” of logical discourse. It does so by having both ontology and logic in a single semantic whole, with Sapta-padaartha (सप्तपदार्थ) providing the ontology, and Anuman-Praman (अनुमानप्रमाण) providing the inferential logic. Sapta-padaarthas are the top-level categories of meanings of words. In Nyaya, they are treated as the ontological primitives that span everything that a human mind can conceptualise. Anuman-Praman is a sub-field of Nyaya that deals with inference. It includes a formalism called Panchaavayava Vaakya (पंचावयव वाक्य), or five-part statement, which gives a method of applying the rules of inference. This formalism of inference, is defined in terms of the ontological primitives, not in terms of a context-free idealized objects like predicates.
- It has a formalized meta-language that deals with the non-idealized ontological primitives, called the Navya-Nyaya-Paribhasha. It is a refined subset of Sanskrit language, designed to write canonical representations of human cognition. Gangeshopadhyay invented this refined subset of Sanskrit language called Paribhasha, which simply means Parishkrit Bhasha (परिष्कृत भाषा) - refined language. Unlike the language of mathematics, which works on idealized mathematical objects, the Navya-Nyaya-Paribhasha allows any Sanskrit word to be used in it. However, it forces one to explicitly spell out cognitive relations between the meanings of these words.
In addition to the above two, there is another sub-discipline that Navya-Nyaya shares with Vyakaran (and to some degree with Mimansa), called Shabdabodha. It is a theory of comprehension. Navya-Nyaya deals generally with knowledge acquired from any means - through sense organs, through inference, through analogy, and through verbal testimony. Shabdabodha is that sub-field, which delves deeply into verbal testimony. It answers fundamental questions of how the grammatical structure of Sanskrit language, is linked with ontological primitives and rules of logic of Nyaya. Over two and half millennia of history, Shabdbodha has matured to such as level that an exhaustive theory has emerged, containing a huge repository of methods, capable of elucidating meaning of any Sanskrit sentence as a ambiguity-free, context-aware formal representation in Navya-Nyaya-Paribhasha. Gadadhara Bhattacharya’s seminal work Vyutpattivaad (व्युत्पत्तिवाद), is the book that brings all of these methods together in one coherent whole.
There have been attempts at representing natural language using formal logic in the Deterministic era of AI. John F Sowa’s work on Conceptual Graphs is one such work of great prominence. In my opinion, the reason for their limited success, was that they all started with some form of formal logic, and tried to counterfit how can natural language statements be expressed in it. Shabdabodha, on the other hands, starts with a natural language, and asks what formalisms are needed to unambiguously represent the full gamut of knowledge a human can grasp from a natural language sentence. And thus there is true possibility of finding new formalisms and abstractions inspired from Shabdabodha that can serve as the basis of symbolic semantic systems, which are far more sophisticated compared to the ones from the Deterministic era, and can complement very well the flexibility offered by systems of Probabilistic era.
What specific techniques from Panini’s Sanskrit grammar can be applied to improve Natural Language Processing (NLP) in AI?
Our research does not directly deal with NLP. We are creating a new software infrastructure based on principles inspired from Nyaya and Vyakaran. But still let me attempt an answer, though with a caveat that much of it is conjecture.
It would be safe to say that Sanskrit is probably the most feature-rich natural language. In the sense that the number of syntactic tools, and their corresponding semantic operations, available in the Sanskrit language are far too many. I am going to give three examples here:
- Sanskrit language has a large number and well-defined types of suffixes or Pratyaya (प्रत्यय), such as: sup (सुप्), tin (तिङ्), krit (कृत्), taddhit (तद्धित्), sanadi (सनादि). The corresponding semantic transforms they perform on the meanings of the Prakriti (प्रकृति), or the root words they attach to, is well-defined. Such exhaustiveness and detailing are not seen in other languages.
- Same can be said about the number of pronouns or Sarvanaam (सर्वनाम). Let’s look at a list: अयम्, इयम्, इदम्, सः, सा, ते, एषः, एता, एतत्, कः, का, के, यः, या, ये, अहम्, त्वम्, इदानीम्, तदानीम्, अत्र, तत्र. For comparison, in English language, there is only one word “he” for all the three - अयम्, सः, and एषः. The Sanskrit pronouns अयम्, सः, and एषः specify the different notions of orientation (near-ness/far-ness) while pointing at the referent using a pronoun, which are left unspecified by “he” in the English language.
- Similarly, the exhaustive listing of types of compounds or Samaas (समास): तत्पुरुष, कर्मधारय, अव्ययीभाव, द्वंद्व, बहुव्रीहि, समाहार etc, and how they affect meanings of the resulting compound word, the samamstapada (समस्तपद), is not as clearly found in other languages.
This is the closest a single natural language can get to the superset of features of all languages. Secondly, Paninian tradition organizes these features as part of a unified system of both syntax and semantics. This allows us to see which of these features are mutually exclusive, and which depend on one another. The knowledge of these (and numerous other) features of Sanskrit, can be used to come up with new formalisms (and data structures and algorithms implementing them) to build an abstract and generic model of natural languages. Because of the huge number and overarching nature of features of Sanskrit, such a model may represent semantics of any natural language, rather than a particular one.
One of the challenges of machine learning based NLP approaches has been their inability to explain the results in symbolic terms. In areas of AI, other than NLP, there have been attempts to build memory-backed neural nets, such as the Differentiable Neural Computer by Alex Graves’ team, which have a better shot at explainability. But they have not found much application in NLP yet. Probably because, there are no good symbolic models of human semantics as expressed in natural languages, that can serve as the basis of building such a memory. A generic abstract model of natural language, based on formalisms borrowed from Sanskrit, can be the basis of designing such systems.
How does the rule-based nature of Sanskrit Vyakaran compare to modern programming languages used in AI development?
This is not an appropriate comparison. Modern languages used in AI development such as Python or Rust, are programming languages. They primarily deal with vectors and matrices as primitives, and incrementally build higher-level structures using these primitives. Various architectures such Transformers, or Mamba, or RNNs, or Differential Neural Networks etc provide the basis for building these higher-level structures. Each of these architectures has certain assumptions about intelligence and the real world. If we must make a comparison, we should do so between the underlying assumptions of these architectures and the principles of Sanskrit Vyaakaran. The programming languages used in development of AI are not very relevant.
What challenges might arise when incorporating the complex grammar rules of Sanskrit into AI algorithms for language processing?
When we first thought of using Sankrit knowledge for AI, the primary challenge was to resist the urge to apply the rules of Sanskrit grammar directly to computer systems. The modern computer systems stand on a large and brilliant body of theoretical computer science work done since the 50s. The language and methodology of this body of work has a sort of “impedance mismatch” with the language of Sanskrit Vyakaran and other shastras like Navya-Nyaya. We had to dispassionately study both the streams of knowledge, grasp the concepts from the Shastra, understand the context and purpose in which they were developed, and see what are the gaps in modern computer science, that we can be filled by taking inspiration from the shastra, and then develop our own theories and systems in the language of computer science. This was a tough challenge.
The unique challenge of Sanskrit is that it has hundreds of technical terms which have a different meaning than ordinary usage and this includes scientific, artistic, philosophical, cultural, and biological terms. This ancient language was the vehicle of expression of the minds of ancient Indians, which predates the English language by millenia. Do you think it is possible to use machine translation for Sanskrit given its complex nature?
My work is more focused on using Sanskrit for computer science and AI. This is a question about using computers science and AI for Sanskrit. So again, I am going to attempt an answer with the caveat of some of it being conjecture.
In languages such as English, the position of a given word in a sentence, relative to other words, is extremely consequential to the meaning of the whole sentence. This was a grave challenge because of which NLP achieved limited success till 2017. One of the critical reasons why LLMs succeeded, was a feature of their underlying architecture, called positional encoding (which works in conjunction with another feature called self-attention). These features were able to successfully address the challenge of using the positions of words in a sentence. But this success, is precisely a drawback for interpreting Sanskrit, in which the position of words play almost no role in interpreting the meaning of a sentence. Samaas, Sandhi, and the fact that a large number of texts are in verses, pose further challenges of automated translations.
However, mathematical principles learnt in attention-oriented research behind LLMs, and also more recent attempts like Mamba, are useful. And ground-up efforts to build fresh architectures applying those mathematical principles, and understanding of Sanskrit languages, can definitely lead to success in machine translation, and other useful NLP applications around Sanskrit.
How do you think IKS can broaden the scope of AI by incorporating the First Principles approach of Indian systems.
I’ll try to answer this questions in terms of examples of first principles thinking inherent in IKS. For instance, whenever we think of numbers 1, 2, 3 - we implicitly imagine them to be on a number line, or an element in a set of Natural numbers. But to someone like my father, who never went to a modern school, numbers were Sankhya (संख्या) one of the 24 Guna (गुण) of Navya-Nyaya. Gunas are properties residing in some substance, or Dravya (द्रव्य), in the real world, not some Platonic idealized abstraction like that of a Natural Number. Sankhyas are canonically expressed in the Navya-Nyaya-Paribhasha as oneness, twoness, threeness (एकत्व, द्वित्व, त्रित्व), which are understood to follow rules such as “oneness pervades twoness” (द्वित्वम् एकत्वेन व्याप्तम्), “twoness pervades threeness” (त्रित्वम् द्वित्वेन व्याप्तम्), and so on. Because, wherever there are two fruits, we can infer that there is one fruit. This is a formalization of common-sense. Navya-Nyaya provides similar formalization of common-sense notions such as colors, smells, touch, measurements, distinctions, connection, disjoning, etc. All of them seem to be useful as first principles for giving common sense to machines.
Another example could be Navya-Nyaya’s concept of Jeevatma can help AI systems understand how humans operate and this can help in disciplines related to management and governance. Unlike in Vedanta or Sankhya, Jeevatma is considered a substance, or Dravya, in Nyaya. And each body of a living being has an associated Jeevatma. This substance (Dravya) is considered to be capable of having 9 properties (Gunas), namely:
- Gyaan (ज्ञान) - cognition,
- Sukha (सुख) - happiness,
- Dukha (दुख) - sadness,
- Ichha (इच्छा) - intention/liking,
- Dvesha (द्वेष) - avoidance/disliking,
- Prayatna (प्रयत्न) - effort,
- Sanskaar (संस्कार) - memory,
- Dharma (धर्म) - all remaining tendencies of Jeevaatma that lead to happiness, and
- Adharma (अधर्म) - all remaining tendencies of Jeevaatma that lead to sadness.
There is further discussion on how these properties of Jeevaatma arise and affect each other. Repeated Sukha leads to Iccha, repeated Dukha leads to Dvesha, Ichha and Dvesha leads to Prayatna. Prayatna is that property of the Jeevatma that can make the body, associated with the Jeevatma, move and impact the outside physical world. Dharma and Adharma are those tendencies which causes Sukha and Dukha respectively. Gyaan is cognition, which leads to Sanskaar which is memory. The ideal way to live life according to Nyaya, is to minimize arising of Prayatna due to Iccha and Dvesha, and let Gyaan lead to Prayatna.
Such a model, can help AI systems model the behaviour of conscious beings. They can also be used as formalism in developing management theories of HR and Marketing. Udayanacharya’s Atma-Tatva-Viveka is a brilliant exposition of Nyaya’s view of Atma.
There are other areas of IKS where we can find substantial inspiration to broaden the scope of AI. I am putting here two more examples coming to mind: - Mimansa and Dharmashastra has a treasure trove of ideas relevant to what is currently being dealt by AI Ethics - The notions of Vibaava (विभाव), Anubhaava (अनुभाव), and Sanchaaribhaava (संचारीभाव) from the Rasa-Shastra, can be used to model the whole range of emotions that arise in a human being.
How can our understanding of aesthetics be incorporated into technology where it is both a form as well as a function of the Indian principle that that which is good is aesthetic.
The short answer is - by considering technology as a Devi. I am taking aesthetic liberty in answering this question, so please don’t hold me to Shastra Pramaan. Abhinavagupta seem to see beauty in every aspect of life. For him, rasotpatti (रसोत्पत्ति) is the means to ultimate divinity. Bhartrihari says “साहित्यसङ्गीतकलाविहीनः साक्षात्पशुः पुच्छविषाणहीनः।” - “Those devoid of literature, music, and arts are verily animals without horns and tail.”. Contemporary stalwarts like Ravindra Sharma of Adilabad, describe civilization as a Saundarya Drishti (सौंदर्य दृष्टि) - an Aesthetic Vision.
The only true way of bringing aesthetics to technology, is to produce technologists who have that Saundarya Dristhi, who are poets and artists at heart. And the heart can only be moulded with devotion. We, the technologists, need an Ishta (इष्ट) to fall in love with. An Ishta whose Purana (पुराण) would teach us to look at technology with a Saundarya Drishti. Who makes us see technology not just as means to material convenience, but as a process of beautiful abstractions appearing in our minds and manifesting themselves in the physical world. Someone amongst us technologists, has to the see the process of creation of technology, as a microcosmic reflection of the creation of the world. As Abhinavagupta sees the process of poetry descending in to vaikhari (वैखरी) through the heart of a poet, as a microcosmic reflection of the Parashiva descending in to the manifest world. Someone amongst us needs to write a Purana of the Devi of technology - and preferably in Sanskrit - giving new meanings to ancient words - and discovering appropriate Prakritis and Pratyayas to describe technological concepts. I possibly lack the Pratibha (प्रतिभा) to do so, but I end this by praying to Maa Shakti to produce capable sons who could sing praises to her, in her new forms.



